Lopt is a multi-modal deepfake classification framework leveraging ViT and TimeSformer based architecture.
Lopt is a multi-modal deepfake classification framework leveraging transformer-based architectures for high-confidence media authentication. It integrates ViT and TimeSformer models for classifications, optimized via stratified training, augmentation, and parameter-efficient fine-tuning. Built for real-world robustness, Lopt supports scalable inference through a FastAPI backend and offers a React-powered UI for streamlined interaction.
Deepfakes are AI-generated media — often hyper-realistic videos or images — where a person’s face, voice, or identity is altered or replaced with another. Initially a byproduct of generative research (e.g., GANs and diffusion models), deepfakes have rapidly evolved from novelty to existential threat.
📉 Implications: Misinformation, digital harassment, political manipulation, identity theft, and erosion of public trust.

A screenshot comparing a real video of President Barrack Obama with a deepfaked version, Jul. 2019 (Youtube/UC Berkeley/https://youtu.be/51uHNgmnLWI/CC Reuse Allowed)
As synthetic content becomes increasingly indistinguishable from authentic media, we need machine learning models that can see what humans no longer can.
As mention earlier Lopt is designed to analyze and classify images and videos as Real or Fake. It combines:
ViT-based architectures for image classification
TimeSformer-based models for video understanding
Clean and reproducible pipelines for training, evaluation, and deployment
Full-stack implementation for both research and real-world use
This project implements two complementary models for deepfake detection:
Virtus: A Vision Transformer (ViT) based model for image-level deepfake detection with binary classification head.
Base Model: facebook/deit-base-distilled-patch16-224
Results:
Accuracy: 99.20%
Macro F1 Score: 0.9920
Evaluated using classification reports and confusion matrix
Inference Ready: Deployed to Hugging Face 🤗 agasta/virtus
Scarlet: A TimeSformer-based architecture for video-level deepfake analysis with memory-efficient Temporal attention mechanism.
Base Model: facebook/timesformer-base-finetuned-k400
Dataset: FaceForensics++
Results:
Accuracy: 96%
Macro F1 Score: 0.958
Evaluated using classification reports and confusion matrix
Inference Ready: Deployed to Hugging Face 🤗 agasta/scarlet
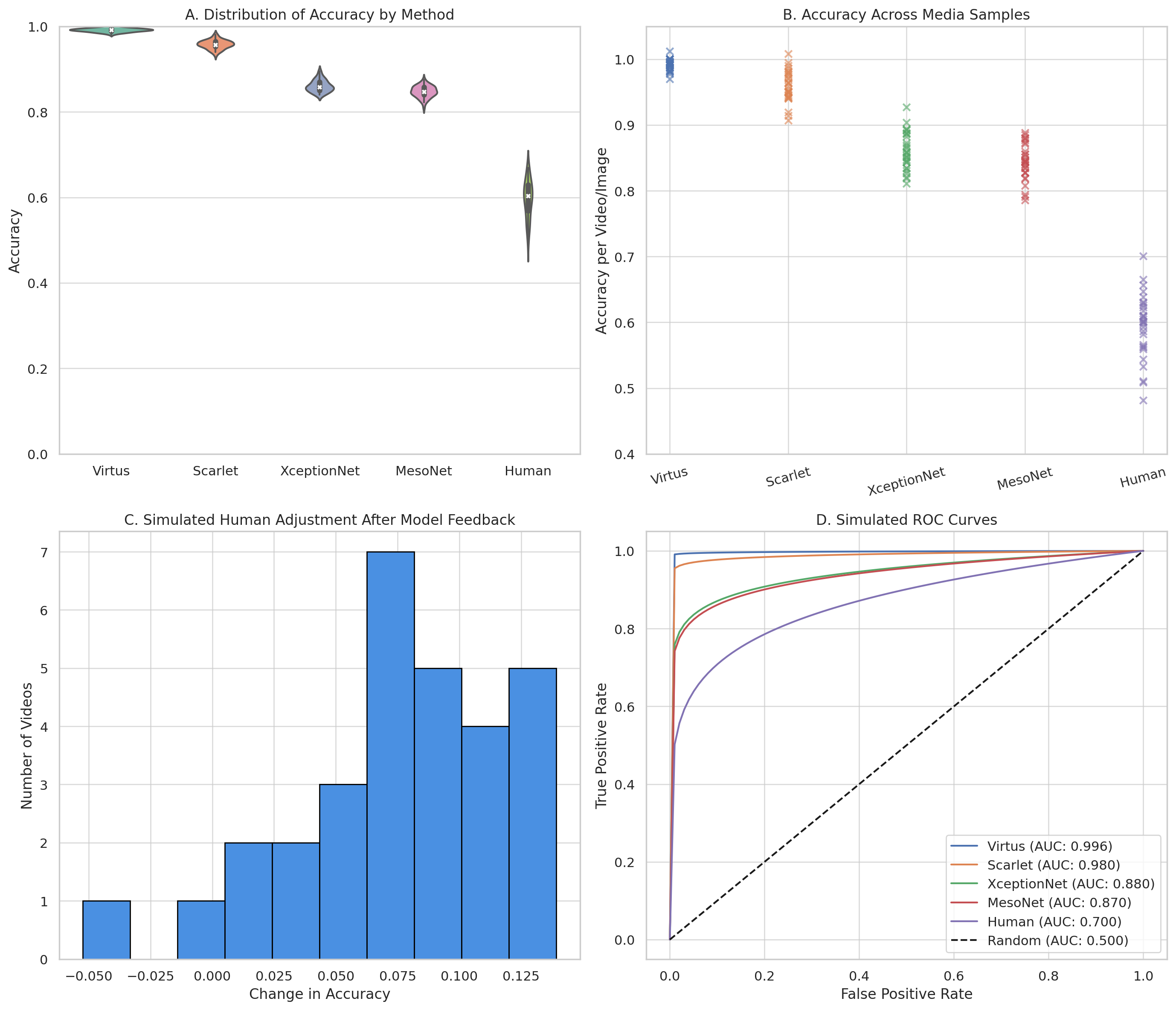
Comparative evaluation of deepfake detection performance across modern and legacy models.
Panel A: Distribution of accuracy across models. Virtus and Scarlet, our transformer-based models, demonstrate significantly higher accuracy compared to classical CNNs (XceptionNet, MesoNet) and simulated human baselines. Panel B: Per-media accuracy scatter highlights the stability of transformer-based predictions, while older CNNs and human judgment show more fluctuation. Panel C: Simulated human performance adjustment after exposure to model predictions shows modest gains in accuracy, indicating potential for hybrid decision-making. Panel D: ROC curves reveal the superior discrimination power of Virtus (AUC: 0.996) and Scarlet (AUC: 0.980), outperforming traditional models and simulated human performance.
Existing deepfake detection solutions often suffer from two major pitfalls:
Modality Fragmentation — Separate tools for image and video analysis, with little interoperability.
Overfitting and Poor Generalization — Models trained on curated datasets fail on real-world, noisy content.
Lopt breaks this cycle by offering a unified, modular architecture that scales across media types — using transformer-based models that are inherently better at learning global, transferable patterns. Here’s how it stands out:
Multi-modal Synergy: Rather than siloing image and video tasks, Lopt treats them as parallel pipelines sharing similar design principles, boosting maintainability and consistency.
Parameter-Efficient Fine-Tuning: Leveraging LoRA and low-rank adaptations, Lopt keeps model updates lightweight — making deployment feasible on constrained hardware without sacrificing performance.
Stratified and Diverse Training: Balanced datasets and augmentation pipelines ensure that Lopt remains resilient across multiple deepfake generation techniques.
Transformer Backbone: ViT and TimeSformer outperform traditional CNN or RNN-based architectures on subtle manipulation cues, especially in low-resolution or noisy media.
Production-Ready Inference: With a FastAPI backend and React frontend, Lopt moves beyond Jupyter notebooks — making deepfake detection accessible to journalists, researchers, and developers alike.
Model | AUC Score |
|---|---|
Virtus | 0.996 |
Scarlet | 0.980 |
XceptionNet | 0.880 |
MesoNet | 0.876 |
Humans | ~0.700 |
Random Guess | 0.540 |
AUC values close to 1.0 indicate high true positive rates with low false positives. Lopt clearly demonstrates superior sensitivity and specificity.
The framework is designed to be modular, allowing for easy integration of new models, datasets, evaluation metrics or with other projects. You can load the model into your project using:
from transformers import AutoModelForImageClassification, AutoFeatureExtractor
model = AutoModelForImageClassification.from_pretrained("agasta/virtus")
extractor = AutoFeatureExtractor.from_pretrained("agasta/virtus")It also provides a user-friendly interface for uploading and analyzing media files. For full training code, dataset preprocessing, and evaluation metrics, check the Virtus model README & Scarlet model README
If you like our project, please consider giving it a vote 💙 — your support means everything!