Many small GPUs, one big model. Production LLM inference, sharded across consumer cards.
ComputePool is a sharded inference network that turns idle consumer GPUs into production AI infrastructure. A Llama-3 70B model needs ~140 GB of VRAM in fp16; an RTX 4090 has 24. So inference today funnels to three hyperscalers while hundreds of millions of capable consumer cards sit idle — each one alone is too small to host a real model.
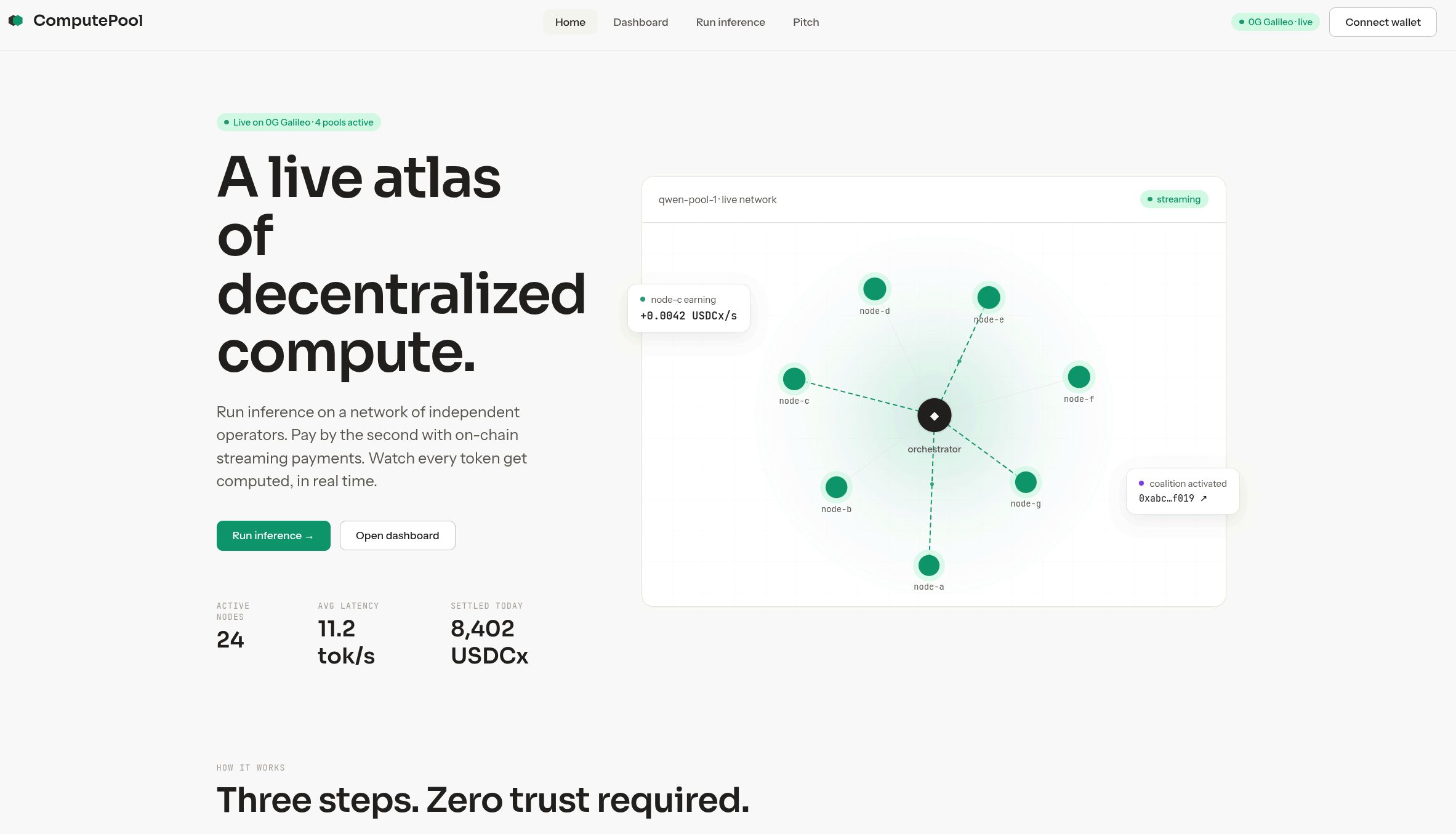
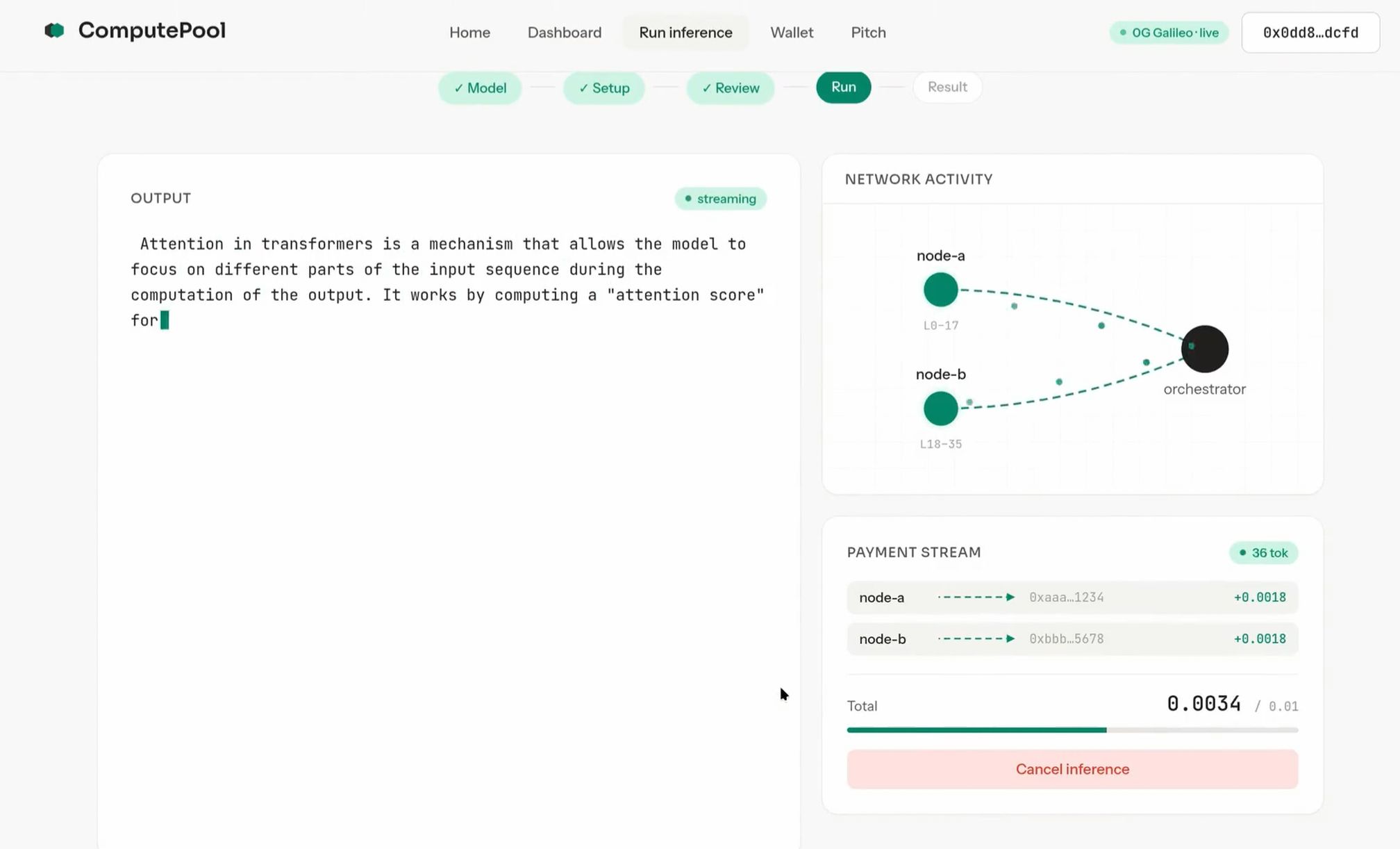
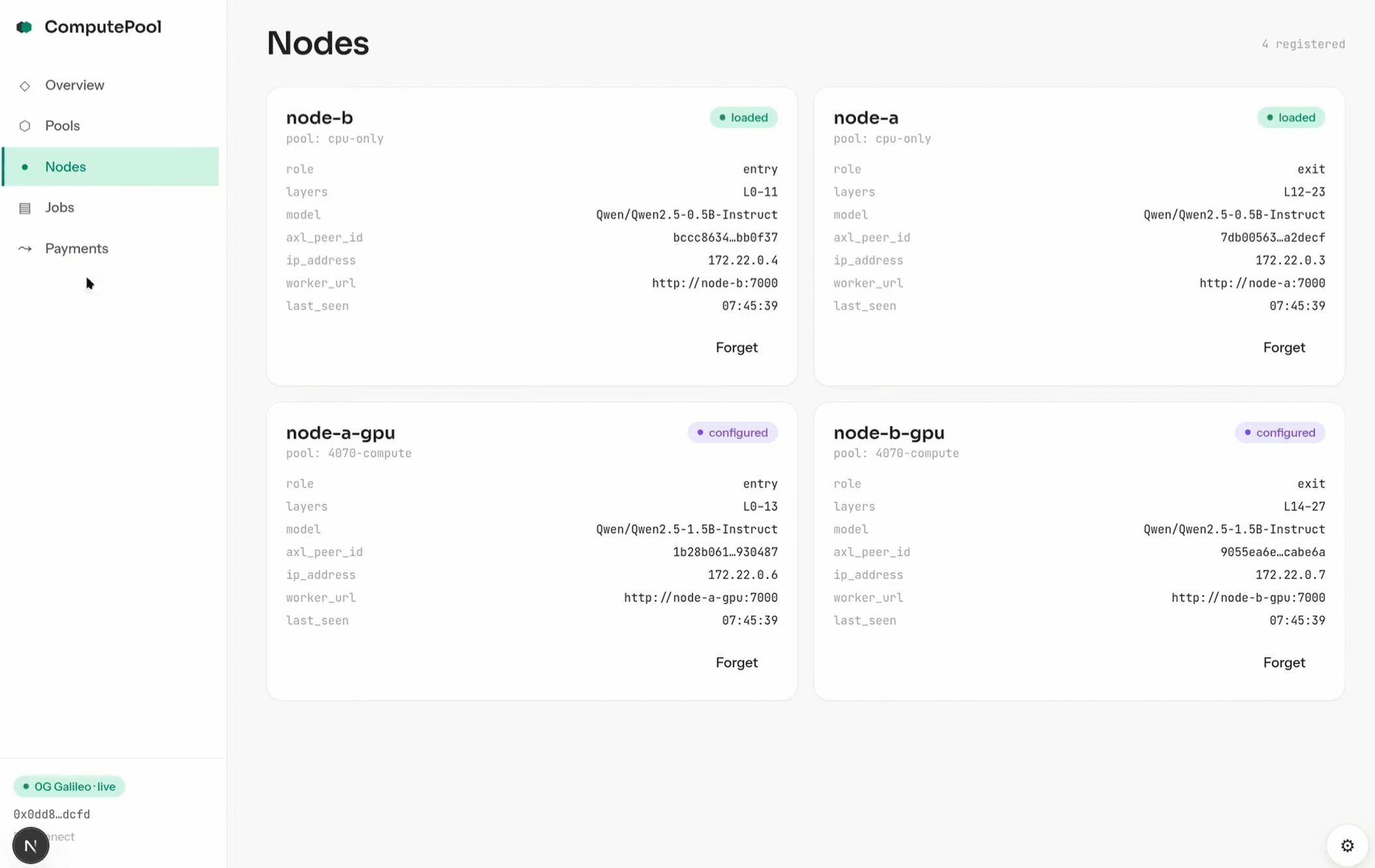
We split the model layer-wise across two or more cards. The entry shard holds embeddings plus the first half of transformer blocks; the exit shard holds the second half plus the lm_head. Hidden-state activations stream peer-to-peer over Gensyn's AXL transport; sampled tokens come back the same way. The orchestrator never touches activations. Throughput tracks single-GPU throughput within noise — the per-token network hop is single-digit milliseconds against a forward pass that takes tens.
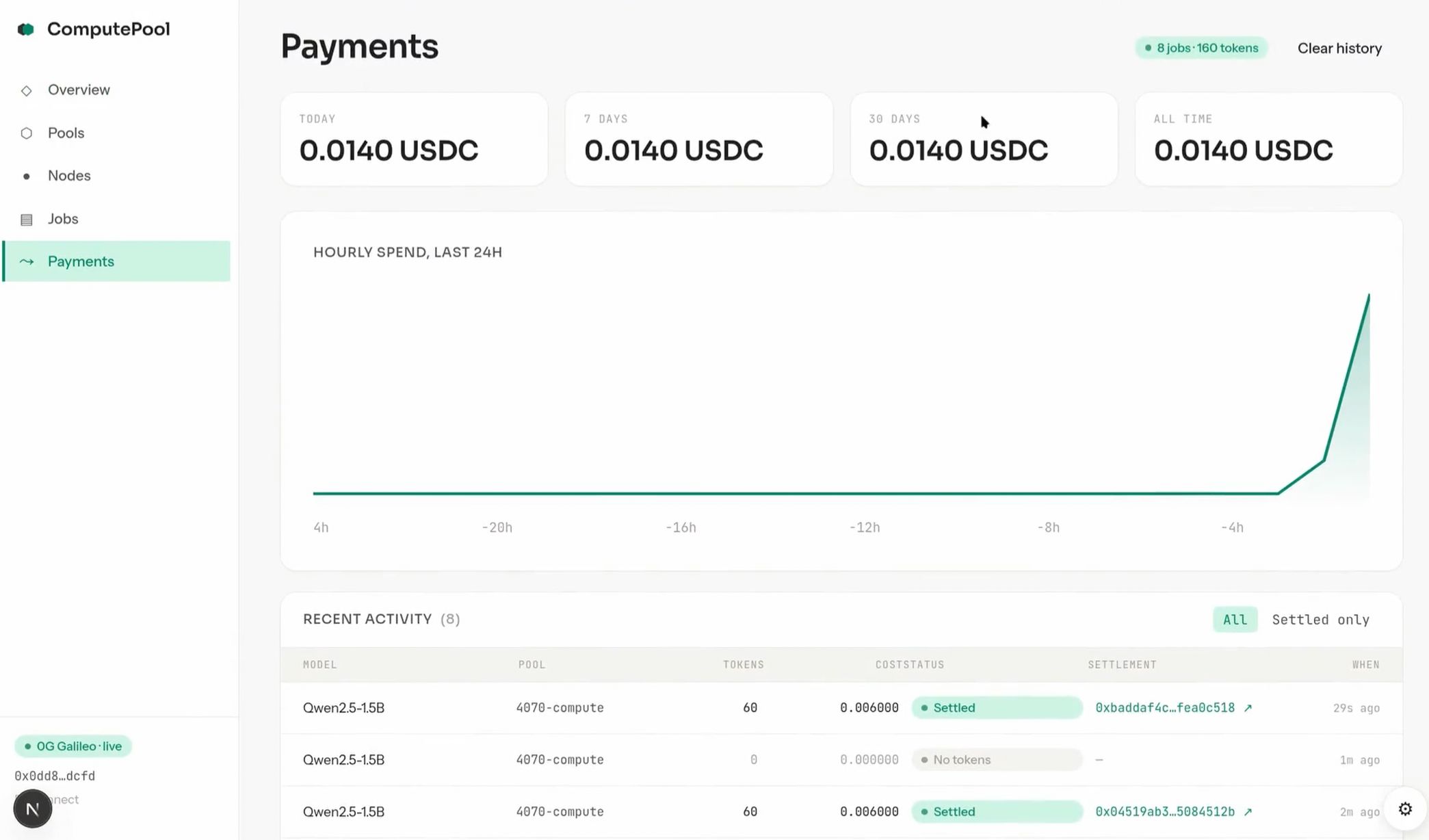
Operators get paid per second of compute. A user opens a session with one x402 voucher; the orchestrator opens a Superfluid USDCx stream that flows to every operator in the coalition while inference runs, and stops the moment the request closes. KeeperHub workflows drive every state transition — propose, activate, stream start/stop, slash — so the full payment lifecycle is auditable and retry-safe.
To make it work we shipped infrastructure back to the sponsor stacks: CREATE2-deployed verified Superfluid contracts on 0G Galileo (the chain's first per-second money primitive), upstream PRs to KeeperHub for a Superfluid plugin and a Coalition plugin (multi-workflow consensus), and a turnkey AXL deployment pattern with prebuilt NVIDIA + CPU Docker images plus Tailscale-native networking (zero exposed ports). Each pool is also minted as an ERC-7857 INFT with encrypted intelligence on 0G Storage. The orchestrator runs inside a TEE so 0G Compute's signing and attestation flow stays intact.
Live on 0G Galileo testnet. Run
make build && make upto bring up the cluster locally;python scripts/e2e_demo.pyruns the end-to-end payment + sharded-inference demo.
Everything below was built from scratch during the hackathon. We structured the build into phases rather than a linear timeline — each phase unlocked the next.
Node communication
Registeration and orcheatrator
UI and Openai compatible endpoin
we are bootstraping and interested in grant programs