DataMind is a decentralized AI data economy designed to enable the discovery, storage, monetization, analysis, and training of AI-ready datasets using decentralized infrastructure.
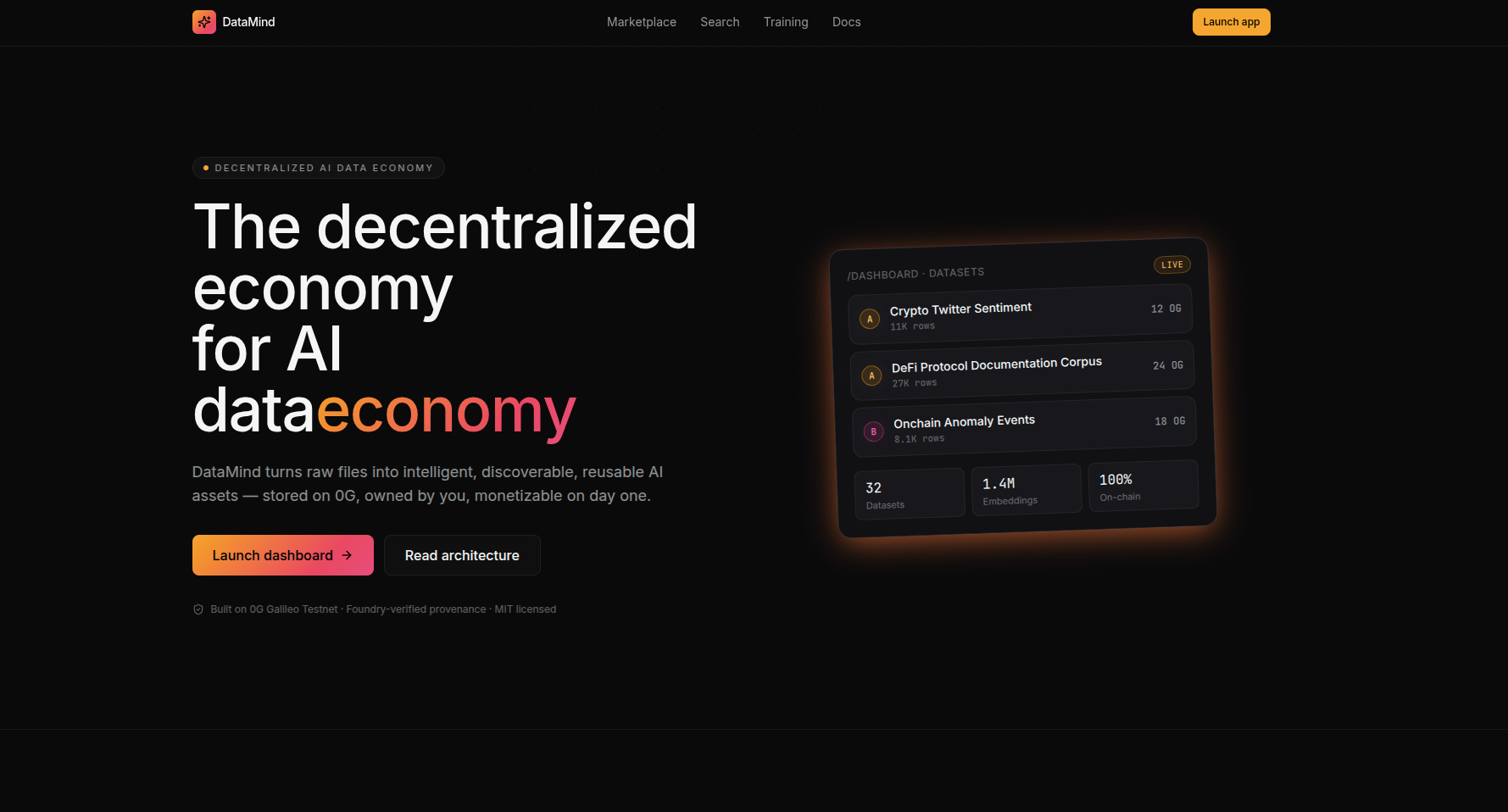
DataMind is a decentralized AI data economy designed to enable the discovery, storage, monetization, analysis, and training of AI-ready datasets using decentralized infrastructure.
The platform combines:
Decentralized storage
AI-native dataset processing
Embedding generation
Dataset reputation systems
Lightweight model training
Ownership provenance
Marketplace discovery
AI compute infrastructure
into a unified platform built for the future AI economy.
DataMind aims to become:
“The infrastructure layer for AI-ready datasets and decentralized model training.”
Modern AI systems depend heavily on:
large datasets
labeled information
domain-specific knowledge
proprietary training data
However, the current AI ecosystem suffers from major issues:
Large corporations control:
dataset access
training pipelines
compute infrastructure
monetization rights
Contributors and creators rarely benefit from the value generated by their data.
Most datasets:
have unclear origins
lack attribution
cannot verify authenticity
cannot track modifications
cannot guarantee licensing rights
This creates legal and ethical concerns.
AI developers spend significant time:
searching for datasets
cleaning data
evaluating quality
validating structure
generating embeddings
Existing platforms provide limited AI-native analysis.
Current dataset platforms are not optimized for:
AI training workflows
semantic search
embedding discovery
training readiness
decentralized compute
Contributors currently have no effective mechanism to:
monetize datasets
track usage
receive attribution
earn recurring rewards
DataMind envisions a future where:
datasets become programmable AI assets
contributors own their data
AI training pipelines become composable
AI-ready datasets become discoverable infrastructure
decentralized storage powers AI economies
AI model development becomes collaborative
The long-term mission is:
“To build the decentralized data infrastructure layer for the AI economy.”
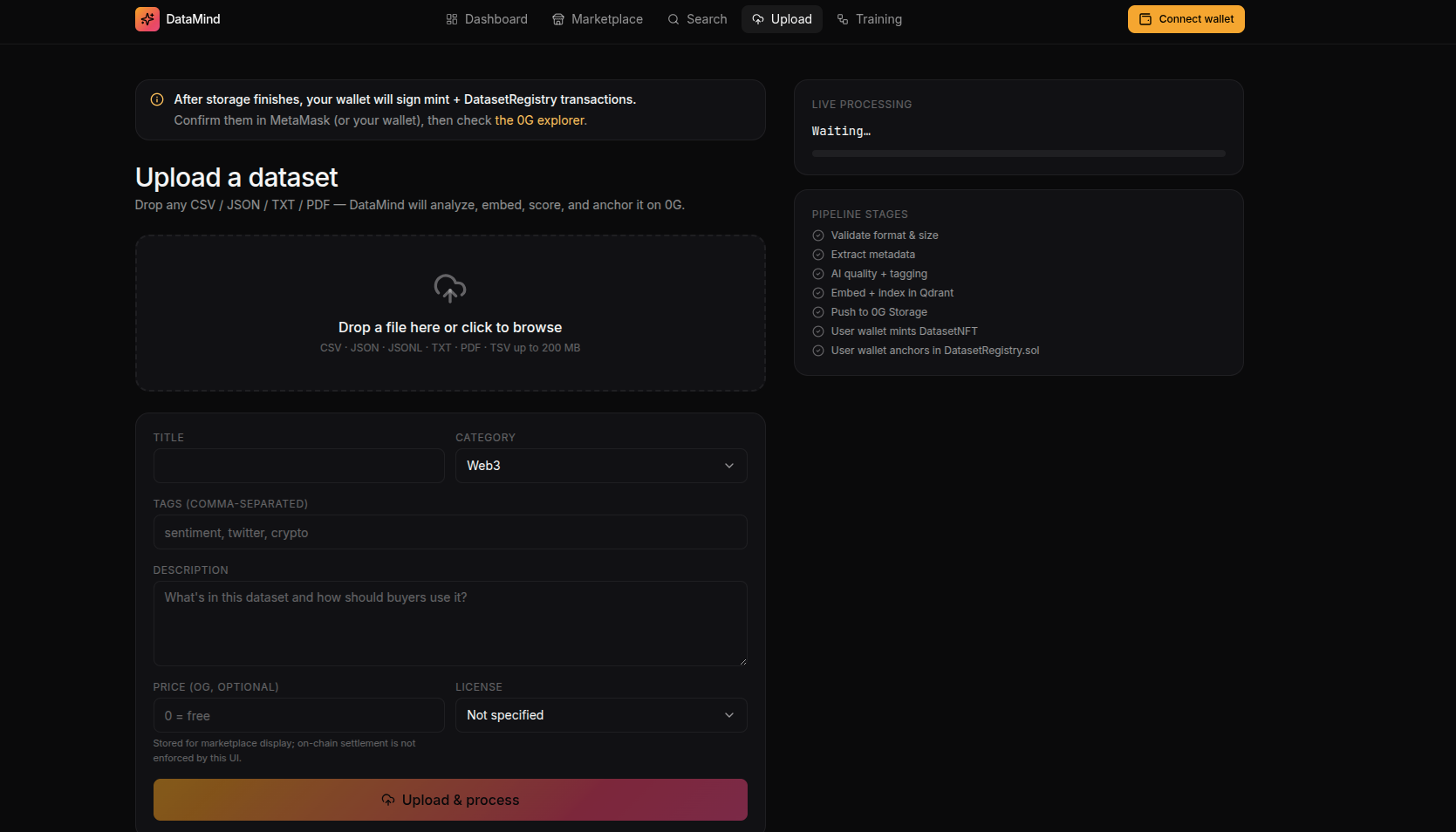
Users can upload:
CSV files
JSON datasets
TXT files
PDFs
image datasets
structured data collections
Dataset Upload
↓
Metadata Extraction
↓
Content Analysis
↓
Embedding Generation
↓
AI Readiness Scoring
↓
0G Storage Upload
↓
Marketplace Publication
The platform automatically extracts:
dataset size
file structure
column types
language detection
topic classification
category labels
tags
licensing metadata
This feature transforms DataMind from a simple storage platform into AI-native infrastructure.
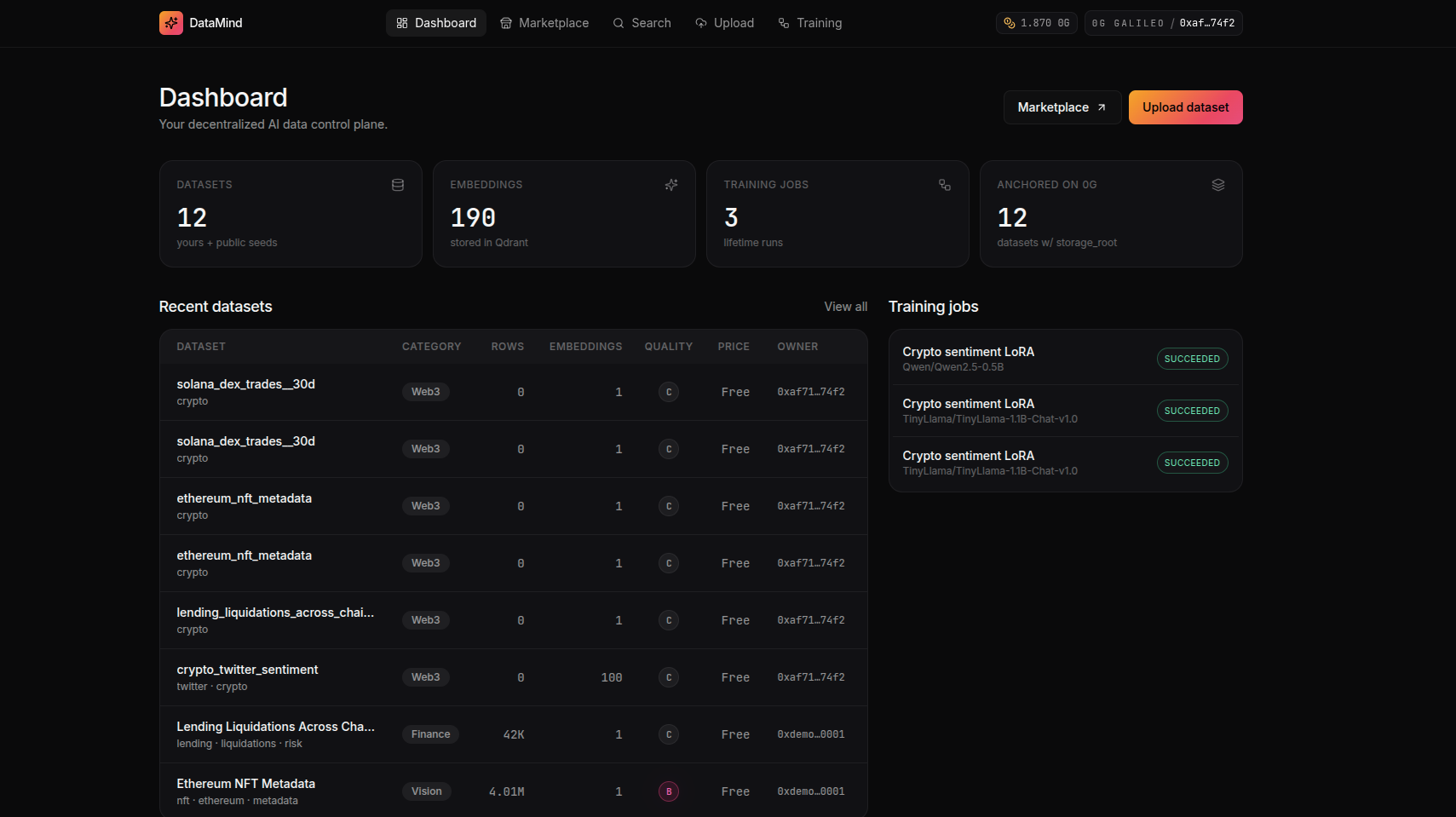
Each dataset is automatically analyzed for:
Measures:
completeness
duplication
missing values
structural consistency
semantic richness
The system generates embeddings for:
semantic search
clustering
retrieval
recommendation systems
Automatically identifies:
finance
healthcare
education
crypto
social media
gaming
legal
research
Detects:
harmful content
unsafe text
duplicated spam
low-quality samples
A custom scoring system evaluates:
training suitability
cleanliness
diversity
token efficiency
embedding quality
DataMind uses 0G Storage as the core decentralized storage infrastructure.
uploaded files
structured data
image collections
processed data
semantic vectors
retrieval indexes
clustering metadata
checkpoints
LoRA adapters
fine-tuned weights
evaluation outputs
creator identity
upload timestamps
licensing metadata
modification history
Benefits include:
censorship resistance
persistent availability
decentralized ownership
transparent storage proofs
composable AI infrastructure
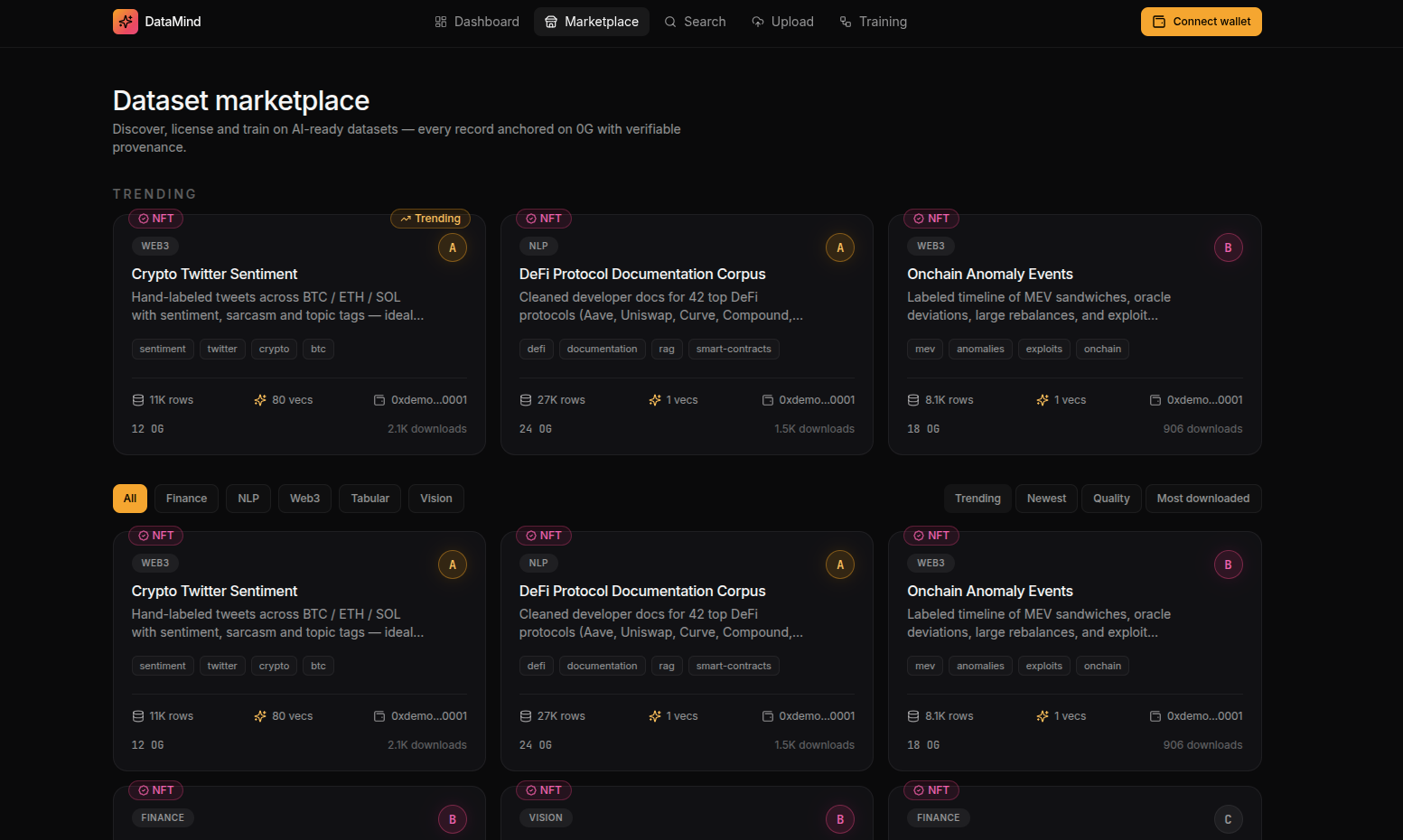
The marketplace enables discovery and monetization of AI-ready datasets.
Each dataset includes:
title
description
tags
categories
preview samples
AI readiness score
reputation metrics
download statistics
licensing information
Users can search using:
keyword search
semantic search
embedding similarity
category filters
trending datasets
popularity rankings
The recommendation engine suggests datasets based on:
usage history
embedding similarity
model compatibility
user interests
Users can launch lightweight training jobs directly from the platform.
LoRA fine-tuning
PEFT adaptation
lightweight transformers
embedding adaptation