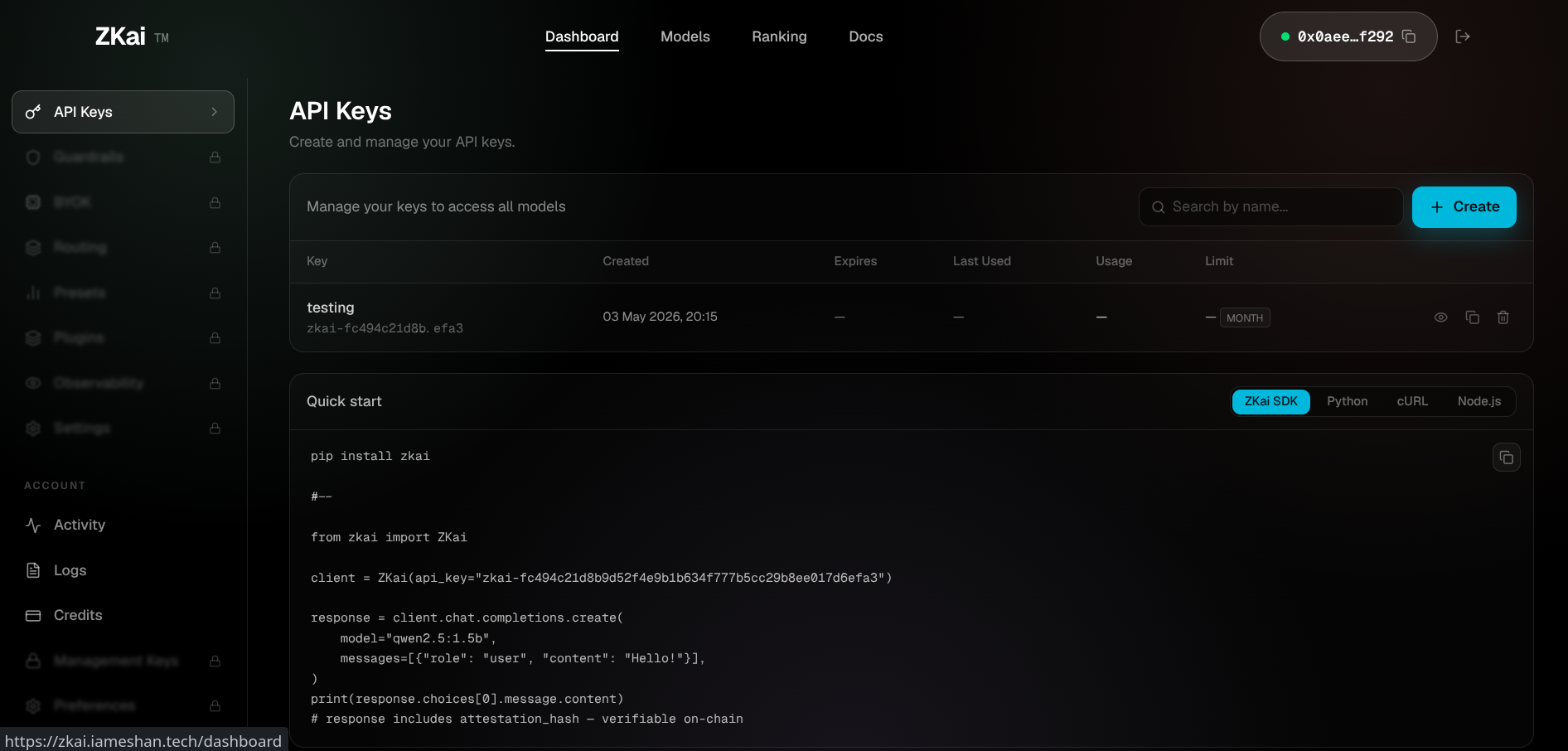
zkai
Private AI inference marketplace. OpenAI-compatible SDK, runs inside TDX-attested enclaves, settles on 0G chain. Every prompt is end-to-end encrypted and every response carries a verifiable on-chain a
视频

技术栈
描述
ZKai is a decentralized AI inference marketplace where every response is cryptographically verified inside a Trusted Execution Environment.
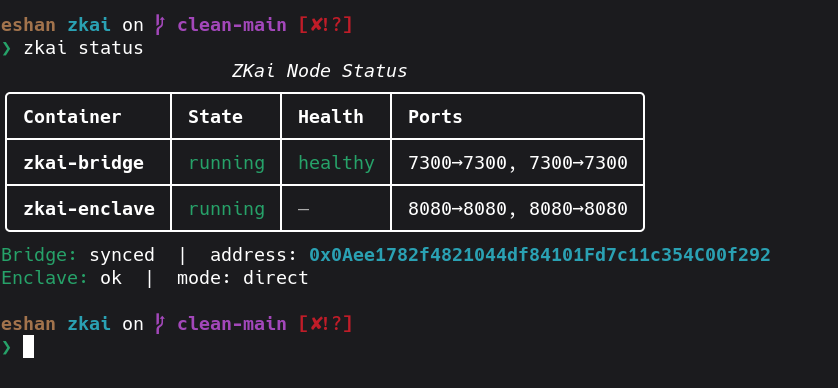
When a developer sends a prompt to ZKai, three things happen that don't happen anywhere else: the prompt is encrypted client-side with the enclave's X25519 public key so even our gateway cannot read it, the model runs inside an Intel TDX-sealed enclave that the host operator cannot peek into, and a SHA-256 attestation hash of the model and the inference gets anchored on the 0G chain. The consumer gets back an OpenAI-compatible response — plus an on-chain receipt they can verify.
Three Solidity contracts on 0G Galileo handle the economic layer. ProviderRegistry tracks active GPU providers. PaymentEscrow holds consumer A0GI deposits and pays providers per inference. AttestationRegistry stores the verifiable hash of every job. Settlement is automatic, on-chain, sub-second.
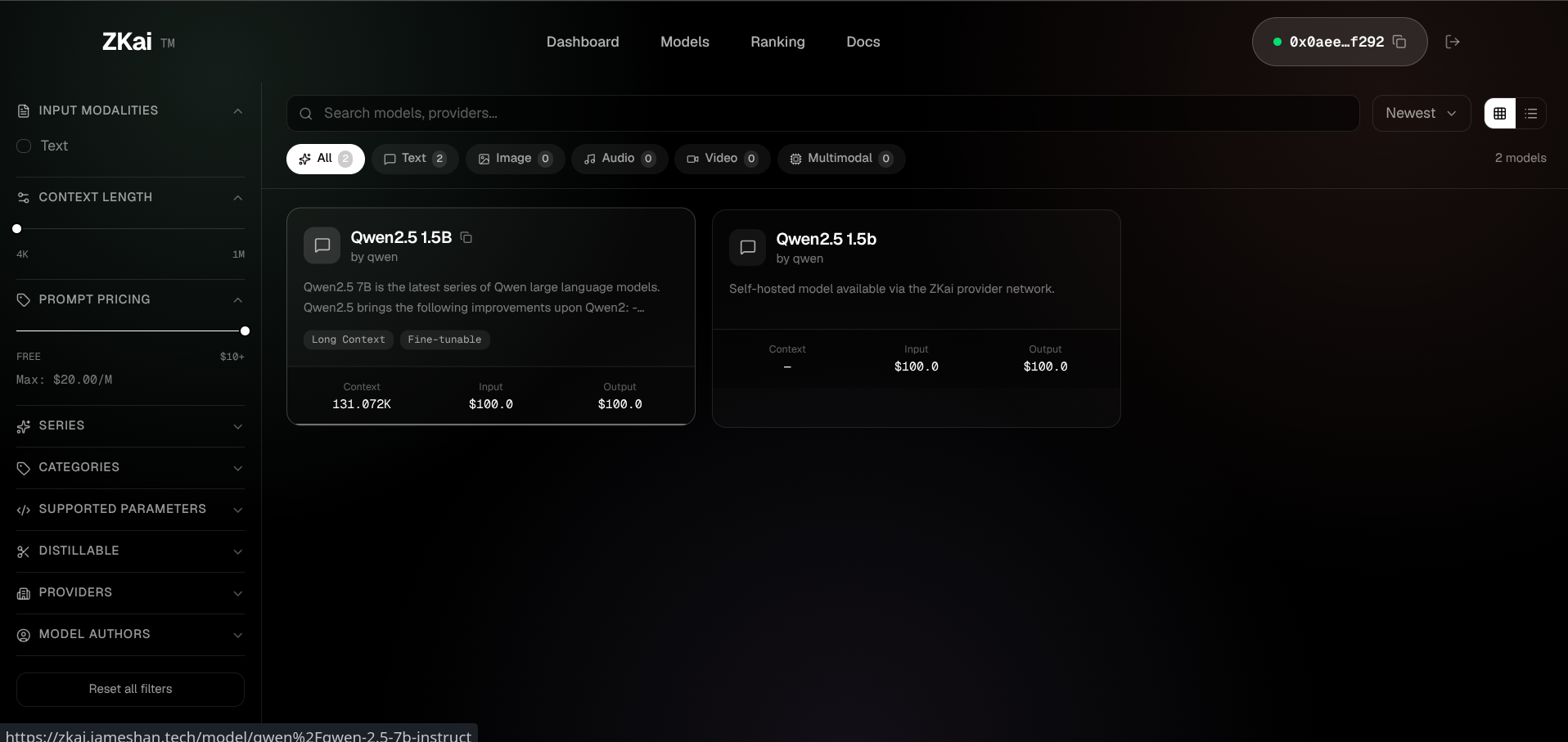
ZKai replaces trust with proof. Existing OpenAI client code drops in by changing two lines. Providers turn spare GPU capacity into A0GI revenue with a single CLI command. The whole stack — gateway, relay, bridge, enclave, dashboard — is open source.
本次黑客松进展
Started from a non-EVM stack that required a ten-minute wallet sync, a custom ZK circuit compiler, and a dedicated proof-server container. Ported the entire system to 0G chain in a single sprint — kept ethers.js, kept Hardhat, kept MetaMask. Wallet startup went from ten minutes to instant. Removed the proof-server entirely.
Deployed three Solidity contracts on 0G Galileo (ProviderRegistry, PaymentEscrow, AttestationRegistry) and rewired the bridge, CLI, frontend, and SDK to talk to them via ethers v6.
Shipped end-to-end client-side encryption with TDX-attested keys. The gateway now sees only opaque ciphertext. Built two new endpoints on the gateway (/api/providers/pubkey and /api/v1/encrypted-chat), wired the WebSocket relay to support multiple HTTP methods so it can fetch the enclave pubkey on demand, and integrated X25519 + ChaCha20-Poly1305 into the Python SDK.
Result: a working end-to-end demo where a Python script using our SDK encrypts a prompt locally, sends it to our Vercel-hosted gateway as ciphertext, the gateway forwards through a Fly.io relay to a TDX-sealed provider running Qwen 2.5, the enclave decrypts inside sealed memory, runs inference, encrypts the response with the same session key, and posts a SHA-256 attestation hash on 0G — all in a single OpenAI-compatible call.
融资状态
Pre-seed. Bootstrapped by the founding team. Not currently raising — focused on shipping the verifiable-inference primitive and onboarding the first ten paying developer teams. Open to angel conversations from operators building in AI infrastructure, privacy, or decentralized compute.